Snakemake Execution on Latch
There are two stages to every Snakemake execution:- Just-In-Time compilation: generates the workflow DAG from the Snakefile and input parameters
- Runtime: execution of the workflow tasks generated during the JIT step.
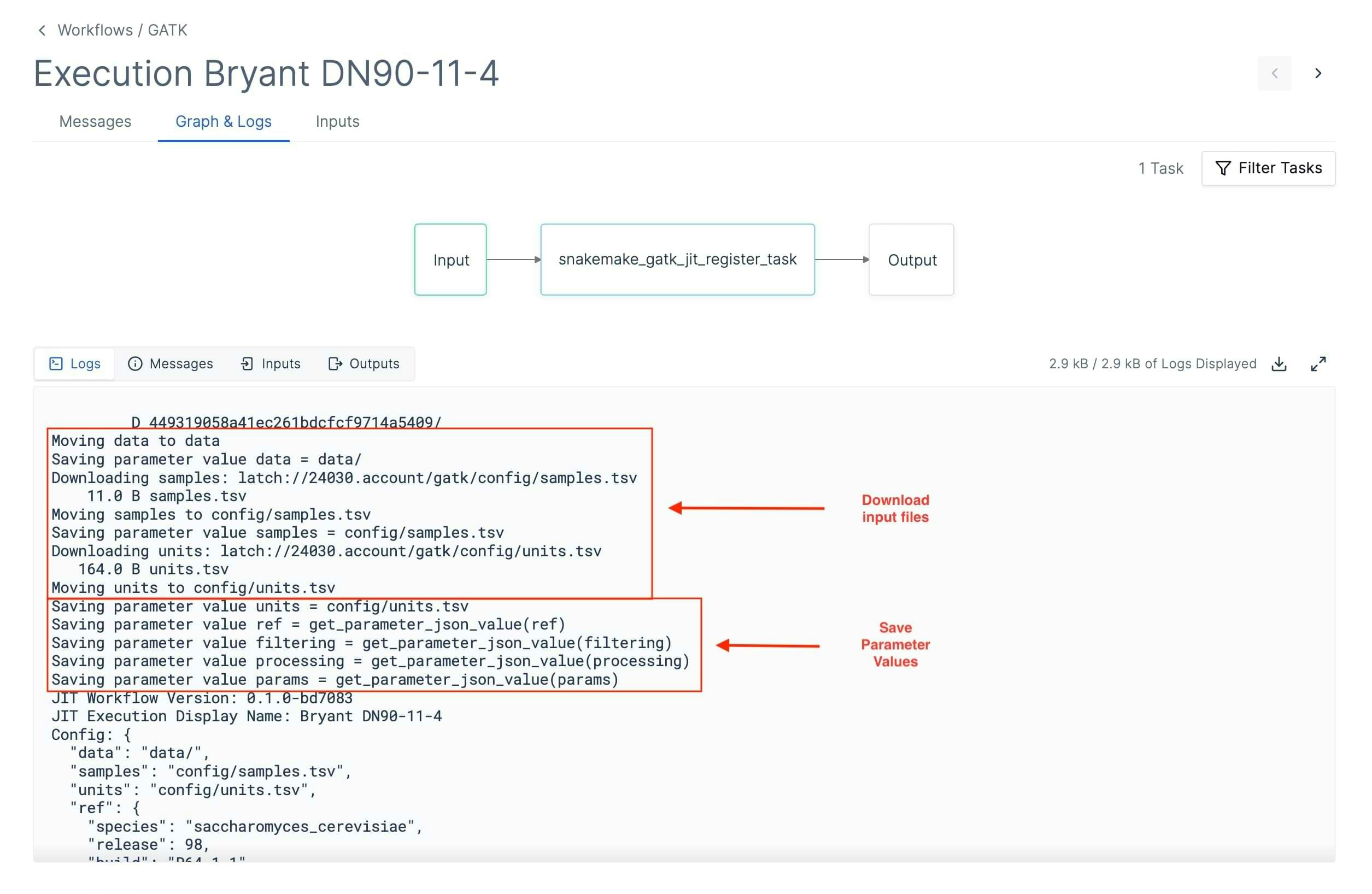
JIT Workflow
The first (“JIT”) workflow does the following:- Create empty input files; this enables the JIT task to mock the file structure at runtime without using unnecessary network bandwidth from downloading the entire file
- Import the Snakefile, calculate the dependency graph, and determine which jobs need to be run
- Generate a Latch SDK workflow Python script for the second (“runtime”) workflow and register it
- Run the runtime workflow
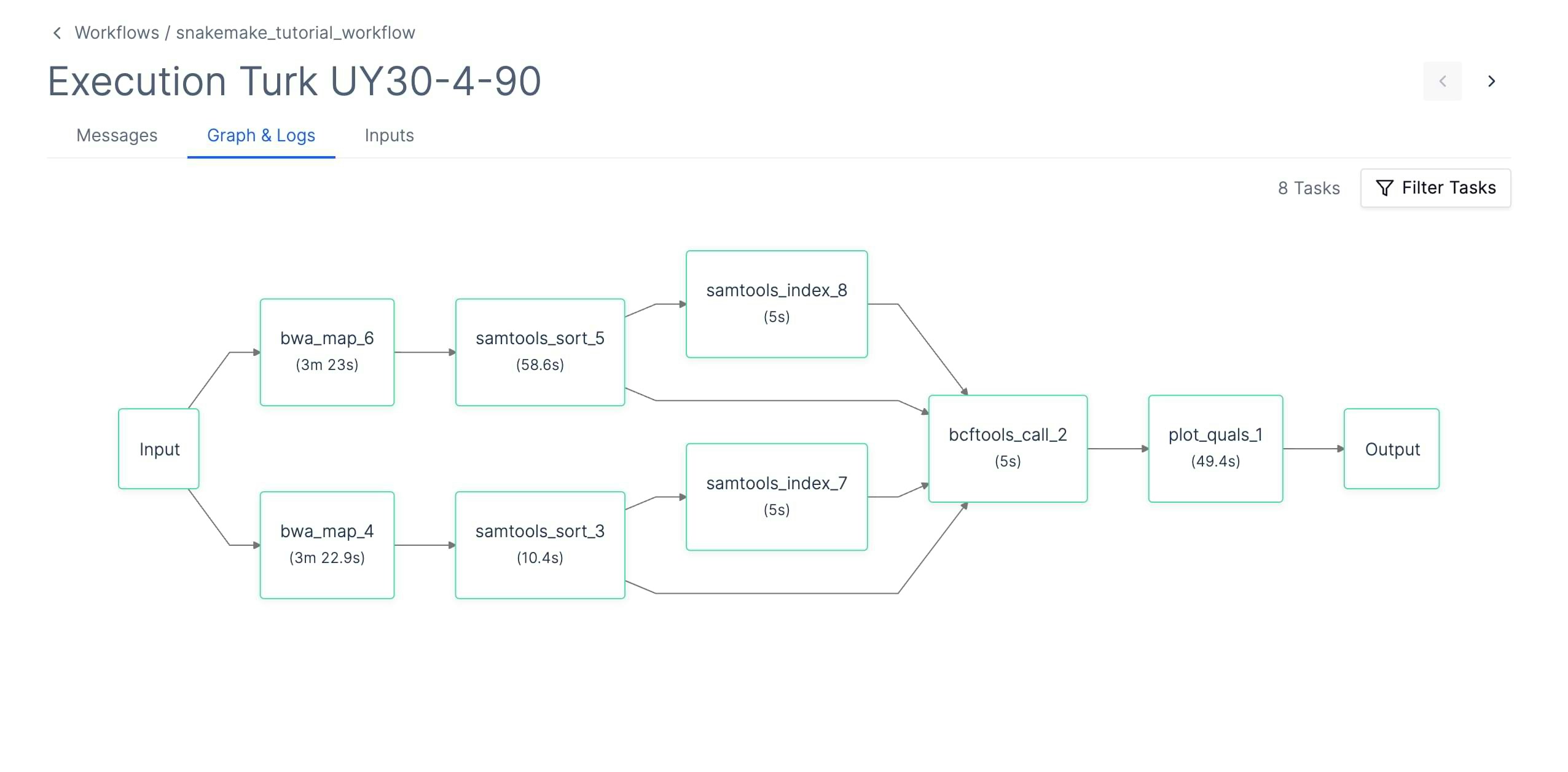
Runtime Workflow
The runtime workflow will spawn a task per each Snakemake job. This means there will be a separate task per each wildcard instantiation of each rule. This can lead to workflows with hundreds of tasks. Note that the execution graph can be filtered by task status. When a task executes, it will:- Download all input files that are defined in the rule
- Execute the Snakemake task
- Upload outputs/logs/benchmarks to Latch Data
Limitations
- The workflow will execute the first rule defined in the Snakefile (matching standard Snakemake behavior). There is no way to change the default rule other than by moving the desired rule up in the file
- Rules only download their inputs, which can be a subset of the input files. If the Snakefile tries to read input files outside of the ones explicitly defined in the rule, it will usually fail at runtime
- Large files that move between tasks need to be uploaded by the outputting task and downloaded by each consuming task. This can take a significant amount of time. Frequently, it’s possible to merge the producer and the consumer into one task to improve performance
- Environment dependencies (Conda packages, Python packages, other software) must be well-specified. Missing dependencies will lead to JIT-time or runtime crashes
- Config files are not supported and must be hard-coded into the workflow Docker image
condadirectives will frequently fail with timeouts/SSL errors because Conda does not react well to dozens of tasks trying to install Conda environments over a short period. It is recommended that all conda environments are included in the Docker image.- The JIT workflow hard-codes the latch paths for rule inputs, outputs, and other files. If these files are missing when the runtime workflow task runs, it will fail